- Hoe voeg ik een disallow toe in robots txt?
- Wat is niet toegestaan in robots txt?
- Hoe negeer ik robots txt?
- Is robots txt juridisch bindend??
- Moet sitemap in robots txt?
- Welk type pagina's moet worden uitgesloten via robots txt?
- Hoe controleer je of robots txt werkt??
- Waar bevindt zich het robot txt-bestand?
- Wat moet robot TXT bevatten??
- Wat gebeurt er als je robots niet gehoorzaamt txt?
- Negeren zoekmachines robots txt?
- Respecteert Google robots txt?
Hoe voeg ik een disallow toe in robots txt?
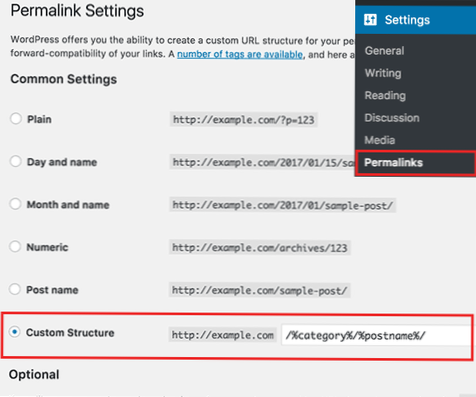
Begin met het instellen van de user-agent-term. We gaan het zo instellen dat het van toepassing is op alle webrobots. Doe dit door een asterisk te gebruiken na de term user-agent, zoals deze: Typ vervolgens "Disallow:" maar typ daarna niets.
Wat is niet toegestaan in robots txt?
Disallow-richtlijn in robots. tekst. U kunt zoekmachines vertellen dat ze bepaalde bestanden, pagina's of gedeelten van uw website niet mogen openen. Dit wordt gedaan met behulp van de Disallow-richtlijn.
Hoe negeer ik robots txt?
Je kunt robots negeren. txt voor uw Scrapy-spider door de ROBOTSTXT_OBEY-optie te gebruiken en de waarde in te stellen op False.
Is robots txt juridisch bindend??
Er is geen wet die stelt dat /robots. txt moet worden nageleefd, noch vormt het een bindend contract tussen site-eigenaar en gebruiker, maar het hebben van een /robots. txt kan relevant zijn in rechtszaken. Vanzelfsprekend, IANAL, en als u juridisch advies nodig heeft, vraag dan professionele diensten aan van een gekwalificeerde advocaat.
Moet sitemap in robots txt?
XML-sitemaps kunnen ook aanvullende informatie over elke URL bevatten, in de vorm van metagegevens. En net als robots. txt, een XML-sitemap is een must-have. Het is niet alleen belangrijk om ervoor te zorgen dat bots van zoekmachines al uw pagina's kunnen ontdekken, maar ook om hen te helpen het belang van uw pagina's te begrijpen.
Welk type pagina's moet worden uitgesloten via robots txt?
Als uw webpagina is geblokkeerd met een robots. txt-bestand, kan het nog steeds in de zoekresultaten verschijnen, maar het zoekresultaat heeft geen beschrijving en ziet er ongeveer zo uit. Afbeeldingsbestanden, videobestanden, PDF's en andere niet-HTML-bestanden worden uitgesloten.
Hoe controleer je of robots txt werkt??
Test je robots. txt-bestand
- Open de testertool voor uw site en blader door de robots. ...
- Typ de URL van een pagina op uw site in het tekstvak onderaan de pagina.
- Selecteer de user-agent die u wilt simuleren in de vervolgkeuzelijst rechts van het tekstvak.
- Klik op de TEST-knop om de toegang te testen.
Waar bevindt zich het robot txt-bestand?
de robots. txt-bestand moet zich in de root van de websitehost bevinden waarop het van toepassing is. Om bijvoorbeeld het crawlen van alle URL's onder http://www . te beheren.voorbeeld.com/ , de robots. txt-bestand moet zich bevinden op http://www.voorbeeld.com/robots.tekst .
Wat moet robot TXT bevatten??
txt-bestand informatie bevat over hoe de zoekmachine moet crawlen, de informatie die daar wordt gevonden, zal verdere crawleractie op deze specifieke site instrueren. Als de robots. txt-bestand geen richtlijnen bevat die de activiteit van een user-agent verbieden (of als de site geen robots heeft.
Wat gebeurt er als je robots niet gehoorzaamt txt?
3 antwoorden. De Robot Exclusion Standard is puur adviserend, het is volledig aan jou of je het volgt of niet, en als je niet iets vervelends doet, is de kans groot dat er niets zal gebeuren als je ervoor kiest om het te negeren.
Negeren zoekmachines robots txt?
Alle toegang voor alle bots
Met andere woorden, zoekmachines negeren het. Daarom heeft deze disallow-richtlijn geen effect op de site. Zoekmachines kunnen nog steeds alle pagina's en bestanden crawlen.
Respecteert Google robots txt?
Google heeft officieel aangekondigd dat GoogleBot niet langer een Robots zal gehoorzamen. txt-richtlijn met betrekking tot indexering. Uitgevers die vertrouwen op de robots. txt noindex-richtlijn heeft tot 1 september 2019 om het te verwijderen en een alternatief te gaan gebruiken.