- Hoe repareer ik de ingediende URL die is geblokkeerd door robots txt?
- Hoe deblokkeer ik robots txt?
- Wat betekent geblokkeerd door robots txt??
- Heeft mijn website een robots txt-bestand nodig??
- Hoe controleer je of robots txt werkt??
- Hoe schakel ik robots txt in??
- Wat is robot txt in SEO??
- Respecteert Google robots txt?
- Hoe zorg ik ervoor dat Google niet wordt geblokkeerd??
- Kan Google crawlen zonder robots txt?
- Hoe schakel ik het subdomein uit in robots txt?
- Hoe blokkeer ik een crawler in robots txt?
Hoe repareer ik de ingediende URL die is geblokkeerd door robots txt?
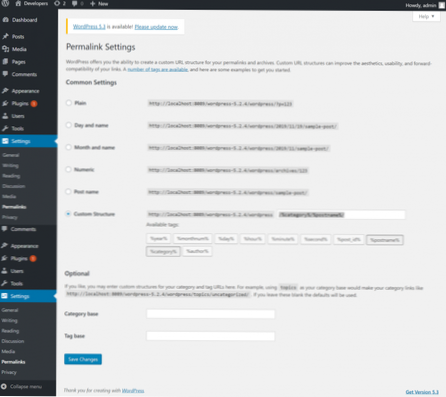
Update je robots.
txt-bestand door de regel te verwijderen of te bewerken. Meestal bevindt het bestand zich op http://www.[uwdomeinnaam].com/robots.txt, ze kunnen echter overal binnen uw domein voorkomen. de robots. txt Tester-tool kan u helpen uw bestand te lokaliseren.
Hoe deblokkeer ik robots txt?
Ga als volgt te werk om het indexeren van uw website door zoekmachines te deblokkeren:
- Inloggen op WordPress.
- Ga naar Instellingen → Lezen.
- Scroll naar beneden op de pagina waar staat "Zoekmachinezichtbaarheid"
- Haal het vinkje weg naast 'Zoekmachines ontmoedigen deze site te indexeren'
- Klik op de knop "Wijzigingen opslaan" hieronder.
Wat betekent geblokkeerd door robots txt??
Als uw webpagina is geblokkeerd met een robots. txt-bestand, kan het nog steeds in de zoekresultaten verschijnen, maar het zoekresultaat heeft geen beschrijving en ziet er ongeveer zo uit. Afbeeldingsbestanden, videobestanden, PDF's en andere niet-HTML-bestanden worden uitgesloten.
Heeft mijn website een robots txt-bestand nodig??
De meeste websites hebben geen robots nodig. txt-bestand. Dat komt omdat Google meestal alle belangrijke pagina's op uw site kan vinden en indexeren. En ze indexeren automatisch GEEN pagina's die niet belangrijk zijn of dubbele versies van andere pagina's.
Hoe controleer je of robots txt werkt??
Test je robots. txt-bestand
- Open de testertool voor uw site en blader door de robots. ...
- Typ de URL van een pagina op uw site in het tekstvak onderaan de pagina.
- Selecteer de user-agent die u wilt simuleren in de vervolgkeuzelijst rechts van het tekstvak.
- Klik op de TEST-knop om de toegang te testen.
Hoe schakel ik robots txt in??
Typ eenvoudig uw hoofddomein in en voeg vervolgens /robots . toe. txt aan het einde van de URL. Het robots-bestand van Moz bevindt zich bijvoorbeeld op moz.com/robots.tekst.
Wat is robot txt in SEO??
de robots. txt-bestand, ook bekend als het robots-exclusieprotocol of -standaard, is een tekstbestand dat webrobots (meestal zoekmachines) vertelt welke pagina's op uw site moeten worden gecrawld. Het vertelt webrobots ook welke pagina's niet moeten worden gecrawld.
Respecteert Google robots txt?
Google heeft officieel aangekondigd dat GoogleBot niet langer een Robots zal gehoorzamen. txt-richtlijn met betrekking tot indexering. Uitgevers die vertrouwen op de robots. txt noindex-richtlijn heeft tot 1 september 2019 om het te verwijderen en een alternatief te gaan gebruiken.
Hoe zorg ik ervoor dat Google niet wordt geblokkeerd??
Een metatag maken
Hier volgen enkele veelvoorkomende metatags die u aan uw HTML-pagina's kunt toevoegen: Voorkom dat bepaalde artikelen op uw site in Google Nieuws worden weergegeven, blokkeer de toegang tot Googlebot-News met behulp van de volgende metatag: <meta name="Googlebot-News" content="noindex, nofollow">.
Kan Google crawlen zonder robots txt?
txt-bestand bestaat niet. Dit betekent dat crawlers er over het algemeen vanuit gaan dat ze alle URL's van de website kunnen crawlen. Om het crawlen van de website te blokkeren, hebben de robots.
Hoe schakel ik het subdomein uit in robots txt?
Ja, je kunt een heel subdomein blokkeren via robots. txt, maar je moet wel een robots maken. txt-bestand en plaats het in de hoofdmap van het subdomein, voeg vervolgens de code toe om de bots te sturen om weg te blijven van de inhoud van het hele subdomein.
Hoe blokkeer ik een crawler in robots txt?
Als u wilt voorkomen dat de bot van Google in een specifieke map van uw site crawlt, kunt u deze opdracht in het bestand plaatsen:
- User-agent: Googlebot. Niet toestaan: /voorbeeld-submap/ User-agent: Googlebot Niet toestaan: /voorbeeld-submap/
- User-agent: Bingbot. Niet toestaan: /voorbeeld-submap/geblokkeerde pagina. html. ...
- User-agent: * Niet toestaan: /