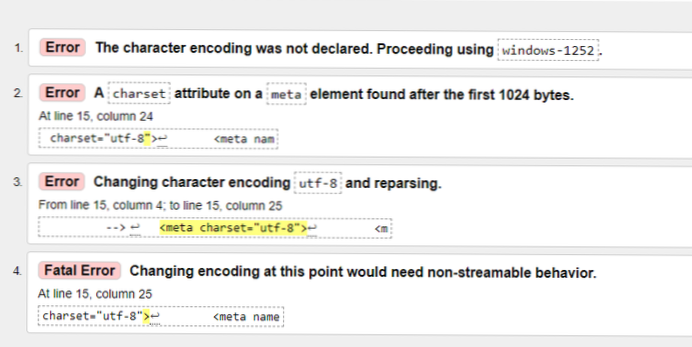
- Hoe kom ik van de UTF-8-fout af??
- Wat is UTF8-fout??
- Hoe verander ik de codering naar UTF-8?
- Hoe wordt UTF8 opgeslagen??
- Hoe los ik Unicode-problemen op??
- Welke karakters zijn niet toegestaan in UTF-8?
- Wat betekent UTF-8 in HTML?
- Waarom heeft UTF-8 de asci . vervangen??
- Is UTF-8 hetzelfde als Asci?
- Wat is het verschil tussen ANSI en UTF-8?
- Waarom wordt UTF-8 gebruikt??
- Wat UTF-8 betekent?
Hoe kom ik van de UTF-8-fout af??
2 antwoorden
- gebruik een tekenset die elke byte accepteert, zoals iso-8859-15, ook bekend als latin9.
- als de uitvoer utf-8 moet zijn maar fouten bevat, gebruik dan errors=ignore -> verwijdert stil niet-utf-8-tekens, of errors=replace -> vervangt niet-utf-8-tekens door een vervangende markering (meestal ? )
Wat is UTF8-fout??
UTF-8 is het dominante tekencoderingsformaat op het World Wide Web. Deze fout treedt op omdat de software die u gebruikt het bestand opslaat in een ander type codering, zoals ISO-8859, in plaats van UTF-8. Er zijn verschillende oplossingen die u kunt gebruiken om uw bestand te wijzigen in UTF-8-codering.
Hoe verander ik de codering naar UTF-8?
Klik op Extra en selecteer vervolgens Webopties. Ga naar het tabblad Codering. Kies in de vervolgkeuzelijst voor Bewaar dit document als: Unicode (UTF-8). Klik OK.
Hoe wordt UTF8 opgeslagen??
Wanneer software die UTF-8 leest een byte tegenkomt die begint met 1, telt het hoeveel enen volgen voordat een 0 wordt aangetroffen. ... Dus een byte van de vorm 110xxxxx zegt dat de eerste vijf bits van een Unicode-teken worden opgeslagen aan het einde van deze byte, en de rest van de bits komen in de volgende byte.
Hoe los ik Unicode-problemen op??
De eerste stap naar het oplossen van uw Unicode-probleem is stoppen met denken aan type< 'str'> als het opslaan van strings (d.w.z. reeksen van door mensen leesbare karakters, a.k.een. tekst). Begin in plaats daarvan aan het type te denken< 'str'> als een container voor bytes.
Welke karakters zijn niet toegestaan in UTF-8?
Merk op dat een byte-ordermarkering (BOM) U+FEFF, ook wel zero-width no-break space (ZWNBSP) genoemd, niet ongecodeerd kan verschijnen in UTF-8 — de bytes 0xFF en 0xFE zijn niet toegestaan in geldige UTF-8. Een gecodeerde ZWNBSP kan in een UTF-8-bestand verschijnen als 0xEF 0xBB 0xBF, maar de stuklijst is volledig overbodig in UTF-8.
Wat betekent UTF-8 in HTML?
charset=UTF-8 staat voor Character Set = Unicode Transformation Format-8. Het is een octet (8-bit) lossless codering van Unicode-tekens. Deze zouden meer licht moeten werpen op het begrip in webontwikkeling en scripting.
Waarom heeft UTF-8 de asci . vervangen??
De UTF-8 verving ASCII omdat het meer tekens bevatte dan ASCII dat beperkt is tot 128 tekens.
Is UTF-8 hetzelfde als Asci?
Voor tekens die worden vertegenwoordigd door de 7-bits ASCII-tekencodes, is de UTF-8-weergave exact gelijk aan ASCII, waardoor transparante retourmigratie mogelijk is. Andere Unicode-tekens worden in UTF-8 weergegeven door reeksen van maximaal 6 bytes, hoewel de meeste West-Europese tekens slechts 2 bytes nodig hebben3.
Wat is het verschil tussen ANSI en UTF-8?
ANSI en UTF-8 zijn twee tekencoderingsschema's die op een bepaald moment op grote schaal worden gebruikt. Het belangrijkste verschil tussen beide is het gebruik omdat UTF-8 ANSI bijna heeft vervangen als het favoriete coderingsschema. ... Omdat ANSI slechts één byte of 8 bits gebruikt, kan het maximaal 256 tekens vertegenwoordigen.
Waarom wordt UTF-8 gebruikt??
Waarom UTF-8 gebruiken?? Een HTML-pagina kan maar in één codering zijn. U kunt verschillende delen van een document niet in verschillende coderingen coderen. Een op Unicode gebaseerde codering zoals UTF-8 kan vele talen ondersteunen en is geschikt voor pagina's en formulieren in elke combinatie van die talen.
Wat UTF-8 betekent?
UTF-8 basisprincipes. UTF-8 (Unicode Transformation-8-bit) is een codering gedefinieerd door de International Organization for Standardization (ISO) in ISO 10646. Het kan maximaal 2.097.152 codepunten (2^21) vertegenwoordigen, meer dan genoeg om de huidige 1.112.064 Unicode-codepunten te dekken.
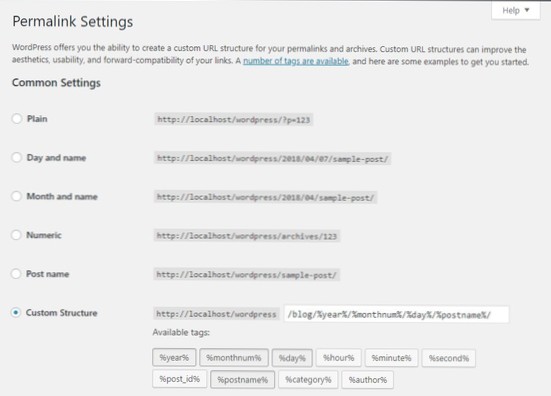
![Categorieën, pagina's maken en posten op Dashboard [gesloten]](https://usbforwindows.com/storage/img/images_1/creating_categories_pages_and_post_on_dashboard_closed.png)